
This post focuses on one of the most popular methodologies, Twelve-Factor App, for building web apps/SaaS products alongside Kubernetes (the open-source container orchestration platform).
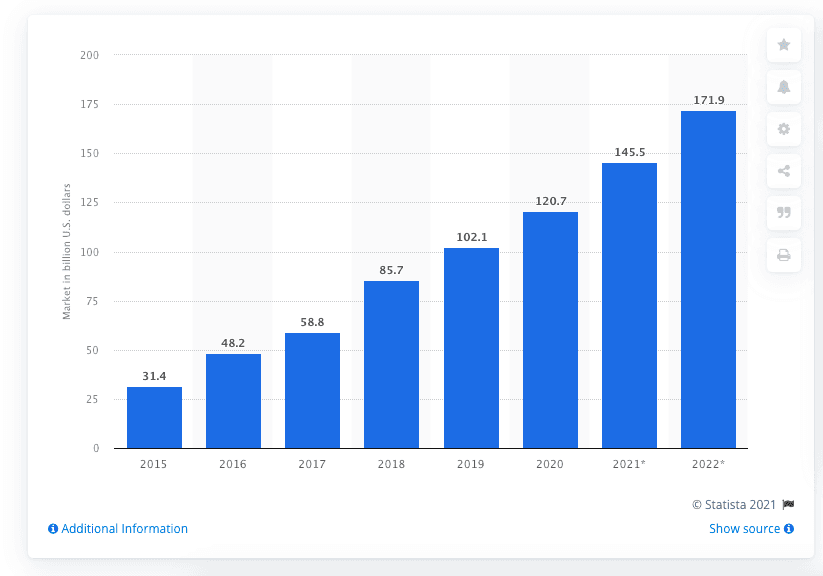
The Software-as-a-Service (SaaS) industry has seen unprecedented growth in recent times. It is expected to be valued at $623 billion by 2023 at a compound annual growth rate of 18%. The need for increased agility and automation will drive the industry’s growth.
86% of organizations said that they expected at least 80% of their software needs to be met by SaaS after 2022 (Via BlueTree AI).
With competition heating up in this space, it's essential to deliver a solid experience to your target customers. Therefore, it is imperative that you use a solid tech stack alongside the latest methodologies to build a secure, scalable & user-friendly digital product.
We focus on the following in this article -
What is the Twelve-factor app (TFA)methodology and why use it?
- What is Kubernetes & why use it alongside TFA?
- How to use TFA & Kubernetes to build a digital product?
- Going beyond the twelve-factor app
- What to use Kubernetes or Docker for your next project?
Let’s get started.
Applications built today are vastly different from those made just a decade back, both in development and infrastructure complexity. As a result, SaaS apps need to scale quickly to serve from a few thousand to possibly millions in a short period. To remain competitive, you will need to design your apps to be agile, ship features faster, and respond to customer feedback quickly.
The twelve-factor methodology helps you do just that!
What are 12 Factor Apps?
The 12 Factor App is a set of principles that describes software making that enables companies to create code that can be released faster, scaled easily. Also, the team can maintain code and configuration consistently and predictably.
Heroku, one of the earliest names in the cloud came up with the concept of the Twelve-Factor App in 2012.
What will organizations gain?
“Good code fails when you don’t have a good process and a platform to help you. Good teams fail when you don’t have a good culture that embraces DevOps, microservices, and not giant monoliths.” — Tim Spann, Developer Advocate
Organizations benefit from embracing the framework primarily in the areas of scalability, flexibility, and security.
Scalability
Scaling in and out is a core concept of 12-Factor apps. When experiencing high traffic, services shouldn’t hang/crash and scale out to ensure a good customer experience. On the other hand, when the traffic is back to normal or lower than average, services should scale down automatically. Hence using 12-Factors will ensure the organization effectively optimizes its infrastructure in terms of cost.
Flexibility
All application processes must be loosely coupled, which results in a lower chance of application breakdown. If affected, only the part of the application (one service) should break. Also, this makes the application highly adaptive to change, resulting in reduced development efforts.
Security
Security is at the core of the twelve-factor methodology. It says that your credentials or any other confidential information should not be in the code repository but within the application’s environment variables. These environment variables are separately stored, and admins should protect them within Vault. This method ensures security and saves organizations from hacks, keeping brand value intact.
What is Kubernetes?
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. The name is derived from the Greek language meaning pilot or helmsman.
K8s as an abbreviation results from counting the eight letters between the “K” and the “s”. Google open-sourced the Kubernetes project in 2014. Kubernetes combines over 15 years of Google’s experience running production workloads at scale with best-of-breed ideas and practices from the community.
Kubernetes has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
The adoption of this system has seen rapid growth too. For instance, the adoption grew from 27% in 2018 to almost 48% in 2020. (Source: Container Journal)
Check out more interesting statistics about Kubernetes here —
Learn more about Kubernetes in this amazing illustrated video -

Key Benefits of using Kubernetes
Right from containerizing monolithic applications, enabling a move to the cloud, and reducing public cloud costs, Kubernetes brings positive outcomes across the board to both development and operations.

Drew Rothstein, Director of Engineering at Coinbase very rightly says,
Companies choose to containerize their applications to increase engineering output/developer productivity in a quick, safe, and reliable manner. Containerizing is a choice made vs. building images, although containers can sometimes be built into images, but that is out of scope (ref).
Besides he also nicely sums up that —
- Containers help engineers to develop, test, and run their applications locally in the same or similar manner that they will run in other environments (staging and production).
- These enable bundling of dependencies to be articulated and explicit vs. implied. Moreover, containers allow for more discreet service encapsulation and resource definition (using X CPUs and Y GB of Memory). You can scale your application horizontally vs. vertically, resulting in more robust architectural decisions.
Problems solved by Kubernetes include —
- Managed/Standardized deployment tooling (deployment).
- Scaling of applications based on some defined heuristic (horizontal scaling).
- Re-scheduling/Moving containers when failures occur (self-healing).
Combining Twelve-Factor App with Kubernetes
Here are The Twelve Factors in brief:
- Codebase: One codebase tracked in revision control, many deploys
- Dependencies: Explicitly declare and isolate dependencies
- Config: Store config in the environment
- Backing services: Treat backing services as attached resources
- Build, release, run: Strictly separate build and run stages
- Processes: Execute the app as one or more stateless processes
- Port binding: Export services via port binding
- Concurrency: Scale-out via the process model
- Disposability: Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity: Keep development, staging, and production as similar as possible
- Logs: Treat logs as event streams
- Admin processes: Run admin/management tasks as one-off processes
Let’s explore them in detail and how you may leverage few services of Kubernetes.
I. Codebase
One codebase tracked in revision control, many deploys
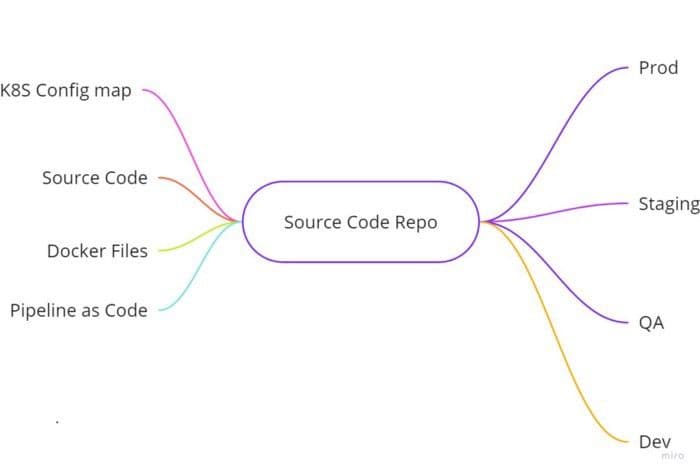
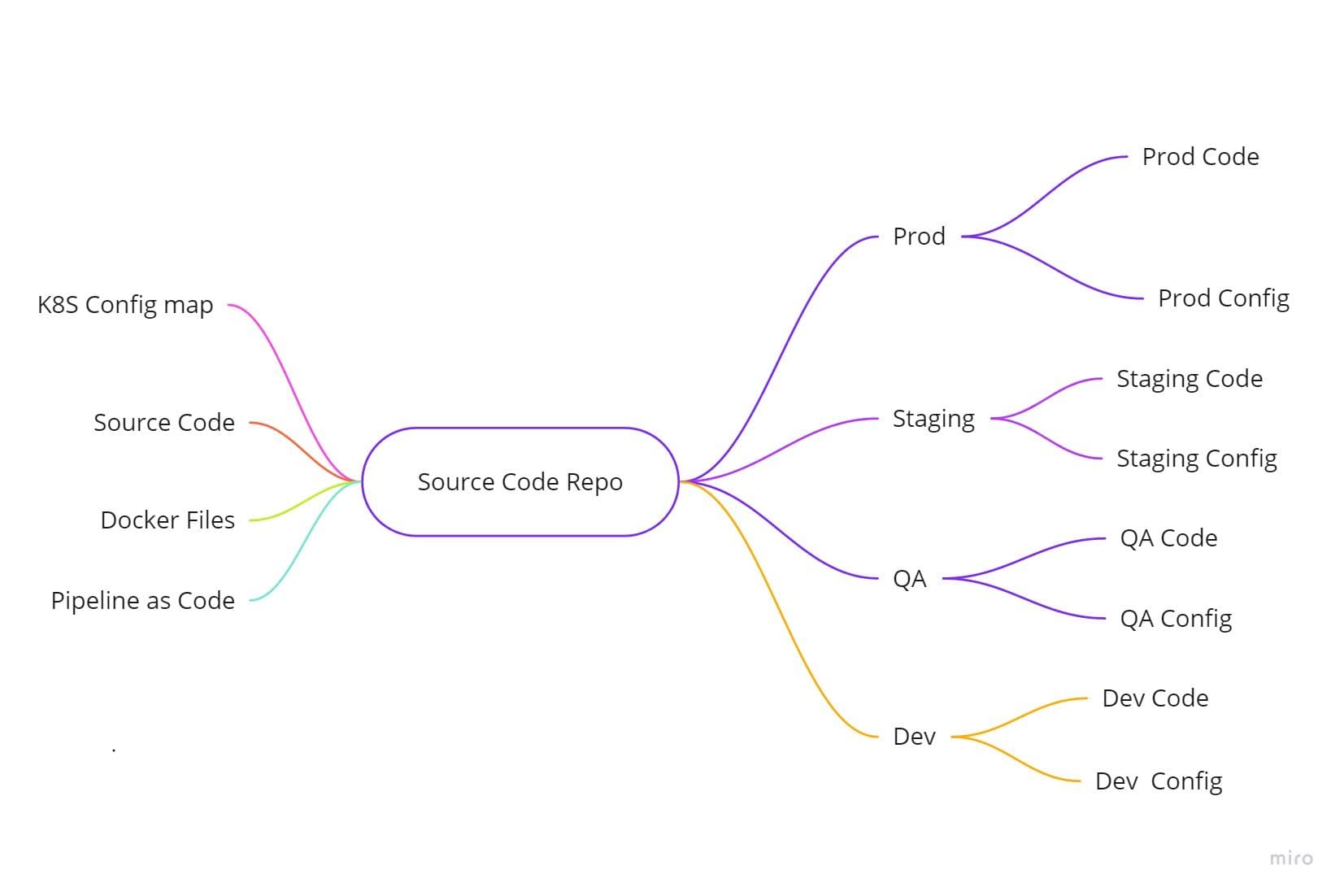
The Codebase factor states that all code must be stored in a single codebase. Thus, essentially enabling us to deploy the same codebase across different environments such as prod/QA/Staging/Dev, just with different configurations.
In the same code base, Kubernetes-related configurations, i.e., Configmap and even docker files, can be stored. This repository should be a part of your CI/CD pipeline, which will eventually take care of the other part of this factor — many deploy.
II. Dependencies
Explicitly declare and isolate dependencies
This factor talks about the packages that the application will require. Also, the same packages must be isolated from code and declare separately. One should never pre-assume that packages required by application would be available in the deployment environment.
In Kubernetes, the application’s microservice would be running independently from other microservices. Each microservices would have an independent file for the containers (docker, this file is called docker file). All dependant packages required to run microservices would be explicitly declared and installed in this container file or docker file while building docker images.
Finally, words of wisdom: the container can include all of the dependencies that the application relies upon and provides a reasonably isolated environment in which the container runs.
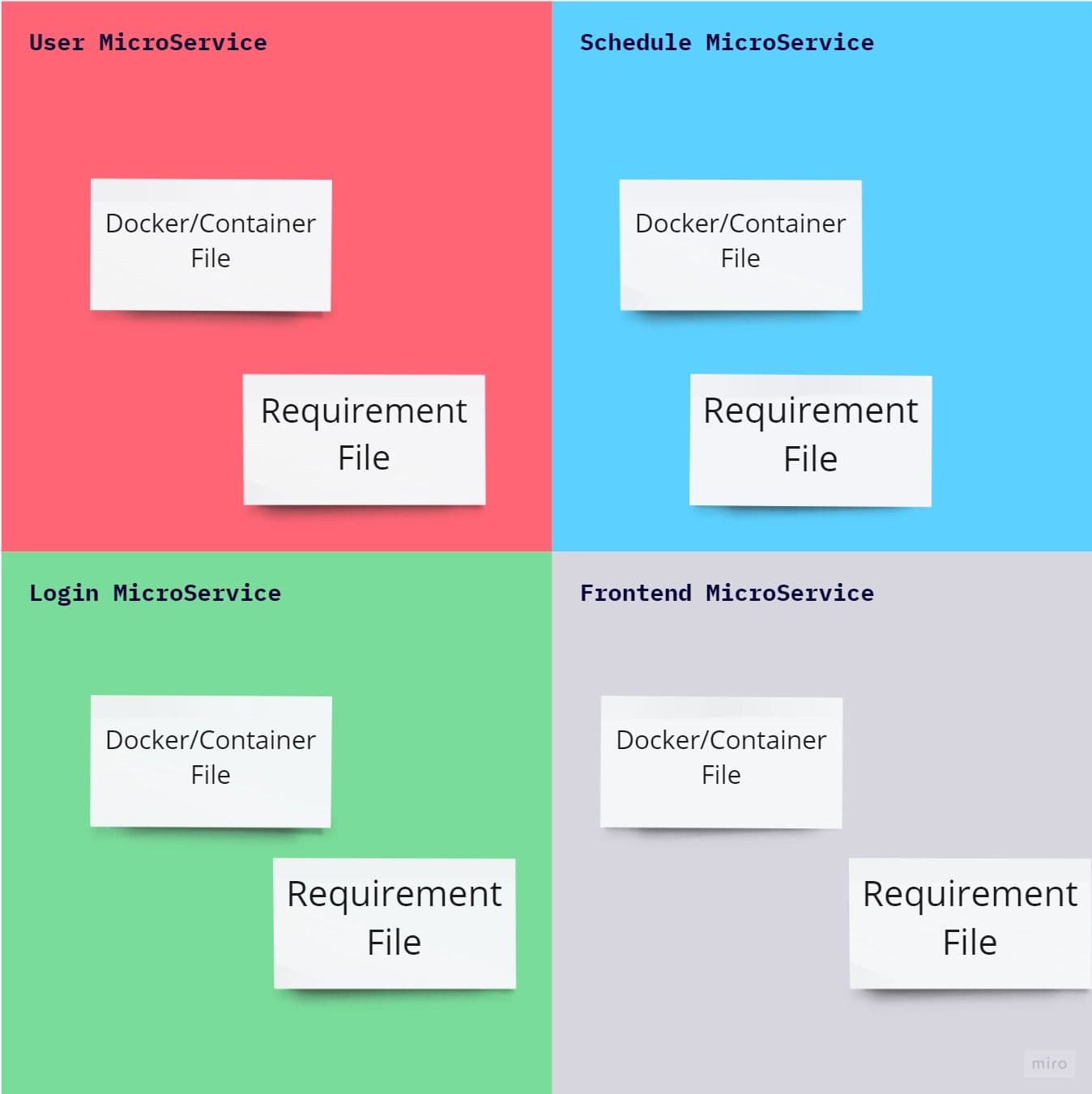
There are two ways to achieve this with example docker and requirement file:
- Put installation dependencies in the docker file itself as the example shown below :
FROM python:3
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir nibabel pydicom matplotlib pillow && \
pip install --no-cache-dir med2image
CMD ["cat", "/etc/os-release"]2. Put installation dependencies in the separate file call requirement.txt and use your generic docker file to create docker images like the example shown below :
requirements.txtmatplotlib
med2image
nibabel
pillow
pydiand use the following generic Dockerfile
FROM python:3
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
COPY . .
CMD [ "python", "./your-daemon-or-script.py" ]III. Config
Store config in the environment
This principle ensures that your source code would remain the same while deploying to a different environment. Generally, the DevOps lifecycle flows through different environment like Dev ->Test -> QA -> Prod. Now let’s assume the situation where developers have stored database configuration in code, hence to make this code work, application code has to be different in all four environments. Voila, this violates the first principle!
Twelve-Factor states to save all external configuration to environment variables. This is easy to change between the deploys without having to change the code in the DevOps lifecycle.
Fortunately, Kubernetes Secrets and Configmaps let you store and manage sensitive information, such as passwords, tokens, database connection strings with authentication details. The information stored in Kubernetes secrets cannot be tracked and traced back even if the application gets compromised.
This is a sample Yaml for fetching the configuration.
apiVersion: v1
kind: Pod
metadata:
name: User-services
spec:
containers:
- name: user-service
image: userservice
env:
# Define the environment variable
- name: MONGO_CONNECTION_STRG
valueFrom:
secretKeyRef:
name: mongsecretes
key: mongo-connection-string # To Store value in env
env:
- name: USER_CURRENT_STATE
valueFrom:
configMapKeyRef:
name: user-prod-valus
key: user_init_state # To Store value in envIn the above example, we store the connection string value to environment variable MONGO_CONNECTION_STRG from Kubernetes secrets. In the same way, we are storing the user’s initial state value from the config map to the environment variable USER_CURRENT_STATE.
Your secrets and Configmap will vary from one environment to other and flows seamlessly along with CI/CD pipeline.
IV. Backing services
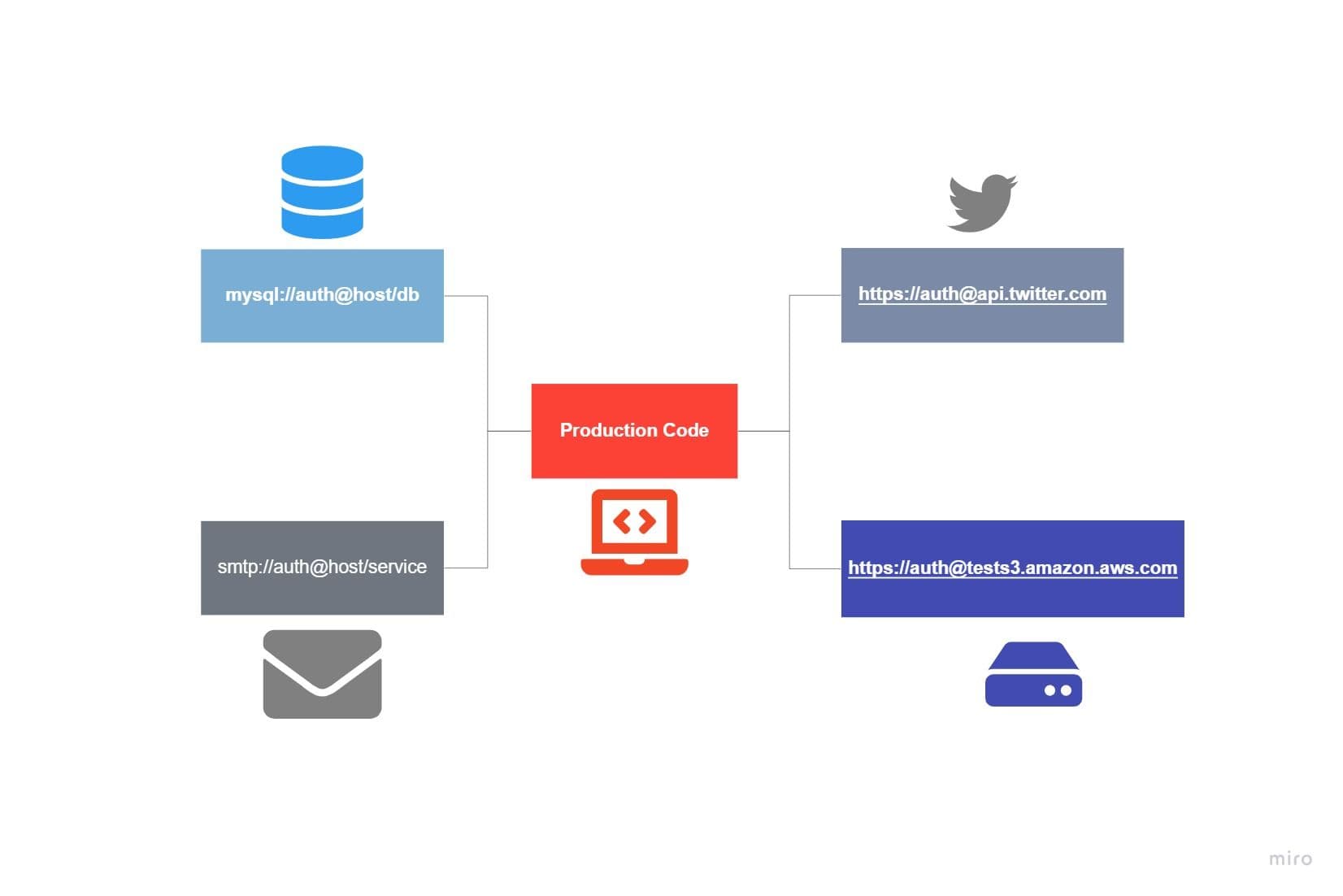
Treat backing services as attached resources
In a 12-Factor App, Backing services means any services required by the application to the consumer over the network. These services could be hosted locally or to any cloud provider. A few good examples of backing services could be databases like MySQL, email services like SMTP, Storage services like s3 buckets.
A 12 Factor app shouldn’t distinguish between the application service and backend service. Backend service should be callable from an HTTPS protocol or a connection string stored in the config. This is already discussed in the previous section.
If any configuration changes have to be made in Backend services, there should be no change in code. Code should be intact! For example, if your application uses a message queuing system, you should be able to change from Inhouse RabbitMQ to Amazon’s SQS or even something else without having to change anything but configuration information.
For 12 Factor apps Designed for Kubernetes, there are two ways you can implement this factor.
- The stateful States within Kubernetes: Backend services deployed in Kubernetes pods are load-balanced through the service component of Kubernetes. You may spin any databases and Queue service in Kubernetes as the configuration is stored in environment variable through Configmap, and communication happens through the service component of Kubernetes.
- The stateful States outside Kubernetes: This setup will be pretty state-forward. All backing service configuration should be stored inside Kubernetes secrets and Configmaps. This will be fetched as an environment variable during deployment on production.
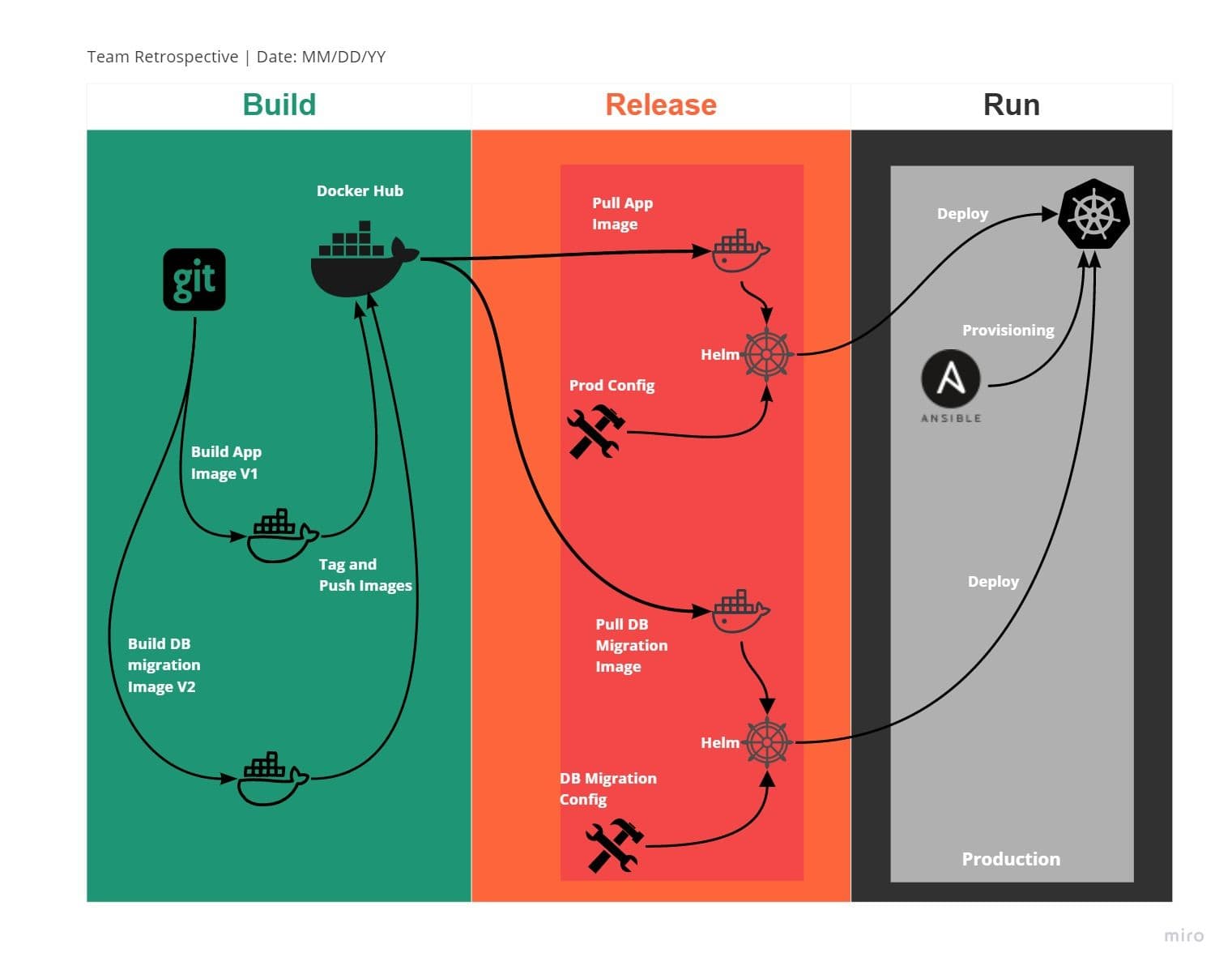
V. Build, release, run
Strictly separate build and run stages
This factor talks about separating three stages for the deployment process, which are :
- Build: This stage will pull the code and convert it into executables like docker image or artifact, which should be store in artifactory repositories like Maven or docker hub or private repository like a harbor.
- Release: In this stage, The configurations stored in the environment variable are applied to the image/artifactory created in the previous stage. The configuration and the image/artifactory will get your services ready to move to the deployment environment. The configurations are stored in Kubernetes Configmap or secrets or environment variables. Generally, for a deployment environment like Kubernetes, helm can be leveraged as a release and deployment tool in CI/CD pipeline.
- Run: This stage runs the application released in the previous stage in a deployment environment such as Kubernetes.
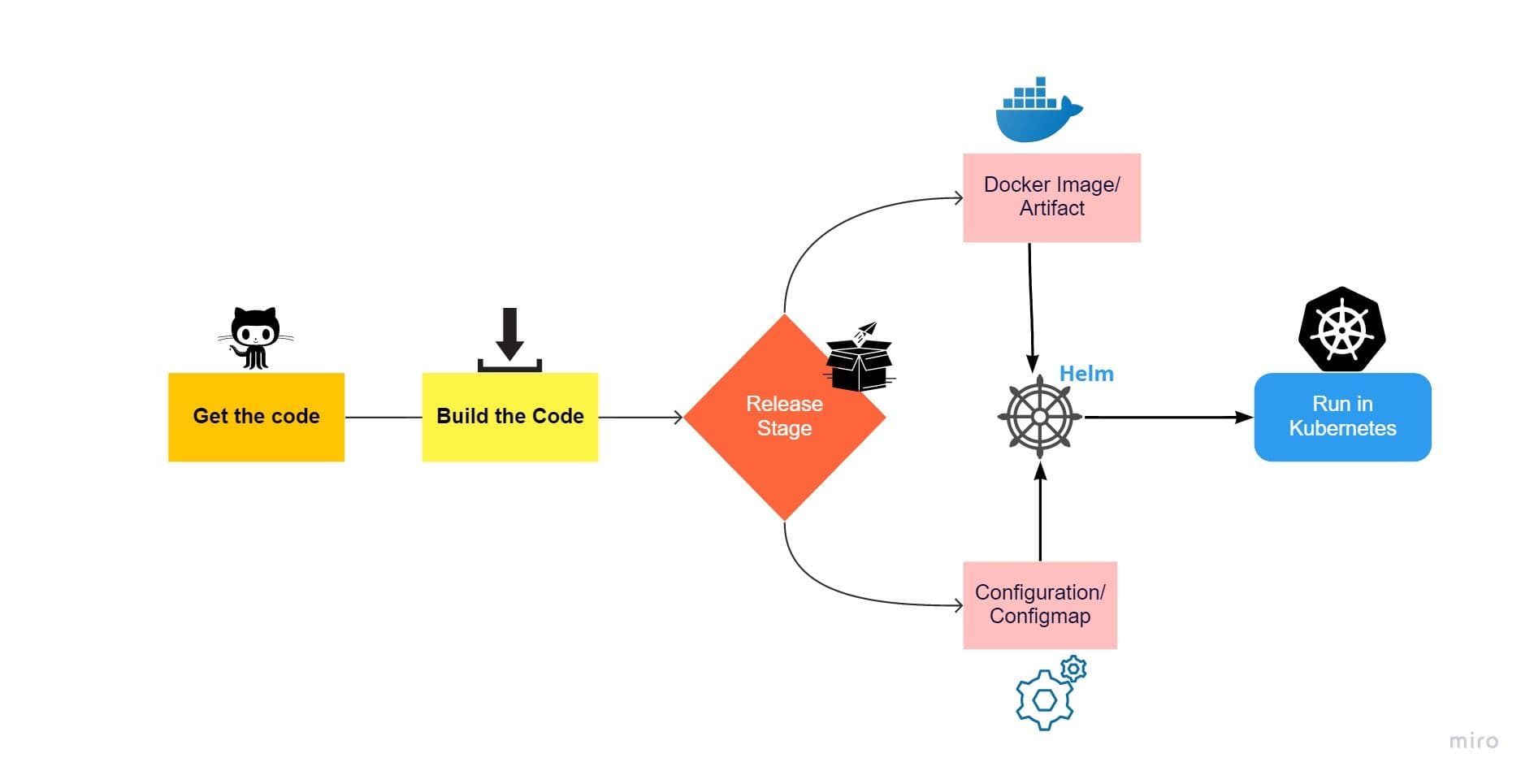
As shown in the image above, In the Release stage, the configuration will be applied with docker image or refectory with the help of helm to be deployed in Kubernetes to run the process.
VI. Processes
Execute the app as one or more stateless processes
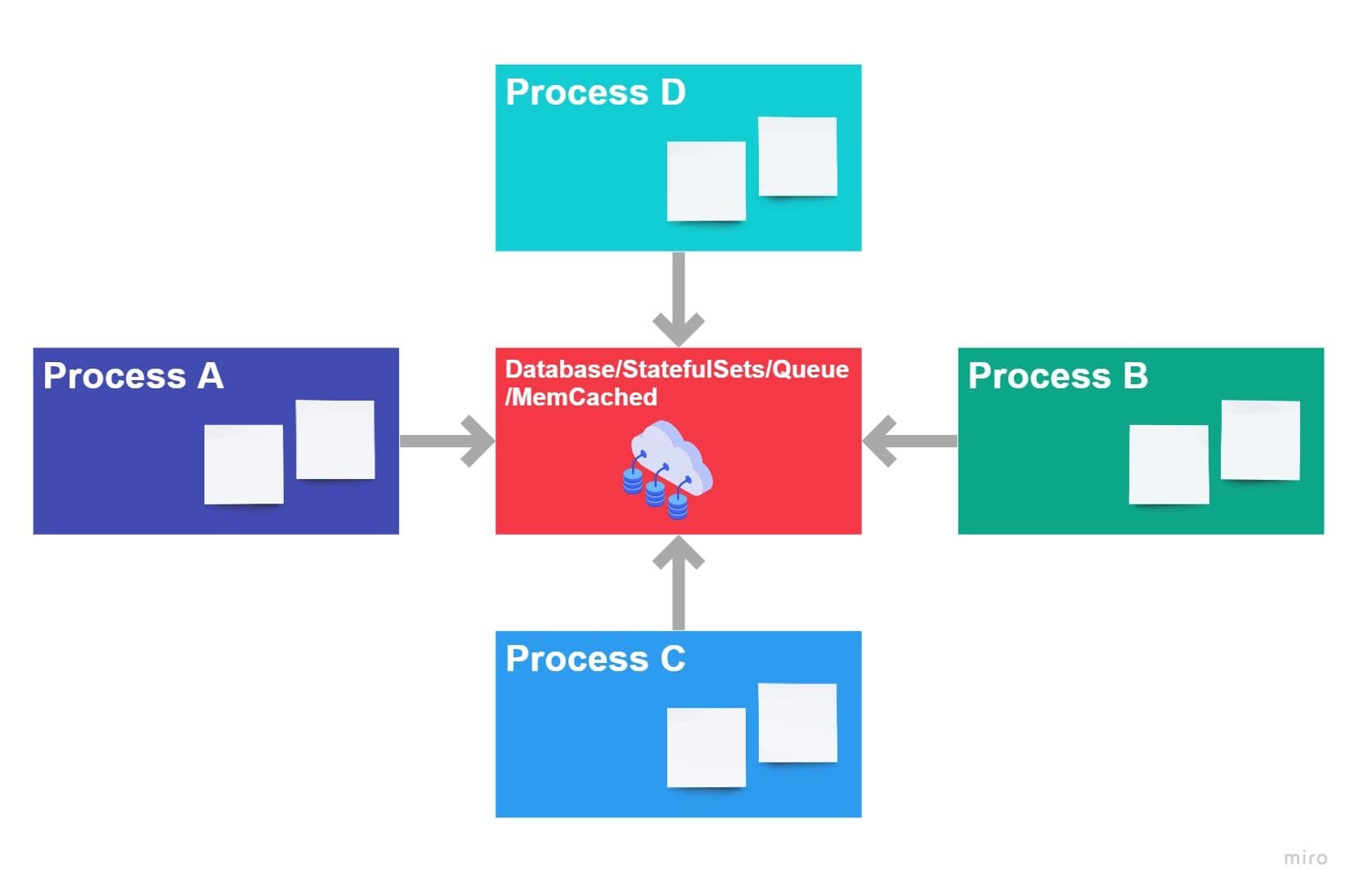
Stateless processes: The process shouldn’t hold any data, i.e., session data or sticky sessions. Any persistent data must preserve inside the backing services, which are discussed in the previous section.
Let’s consider the scenario where developers store session information inside processes, assuming the subsequent request(s) will serve quicker. But, what if services needed scaling, new processes have evolved, and the next request goes to another process just created. The newly evolved process doesn’t have session data and Boom! — To save time, unknowingly, the user experience will suffer.
All data must be preserved in the backing services like Database or Queues or Caching Services to overcome the above challenge. This makes scaling easier. No tracking inside the process! That’s all. In Kubernetes, pods will be serving the user requests. HPA controls the number of pods or scaling of the pod. The number of pods at any given point in time depends on the limits defines in HPA. The number of pods running can go from 1 to N in seconds, depending on traffic volume. Hence preserving data inside pods is a bad idea! Design should leverage backing services as stateful sets to store the data.
VII. Port binding
Export services via port binding
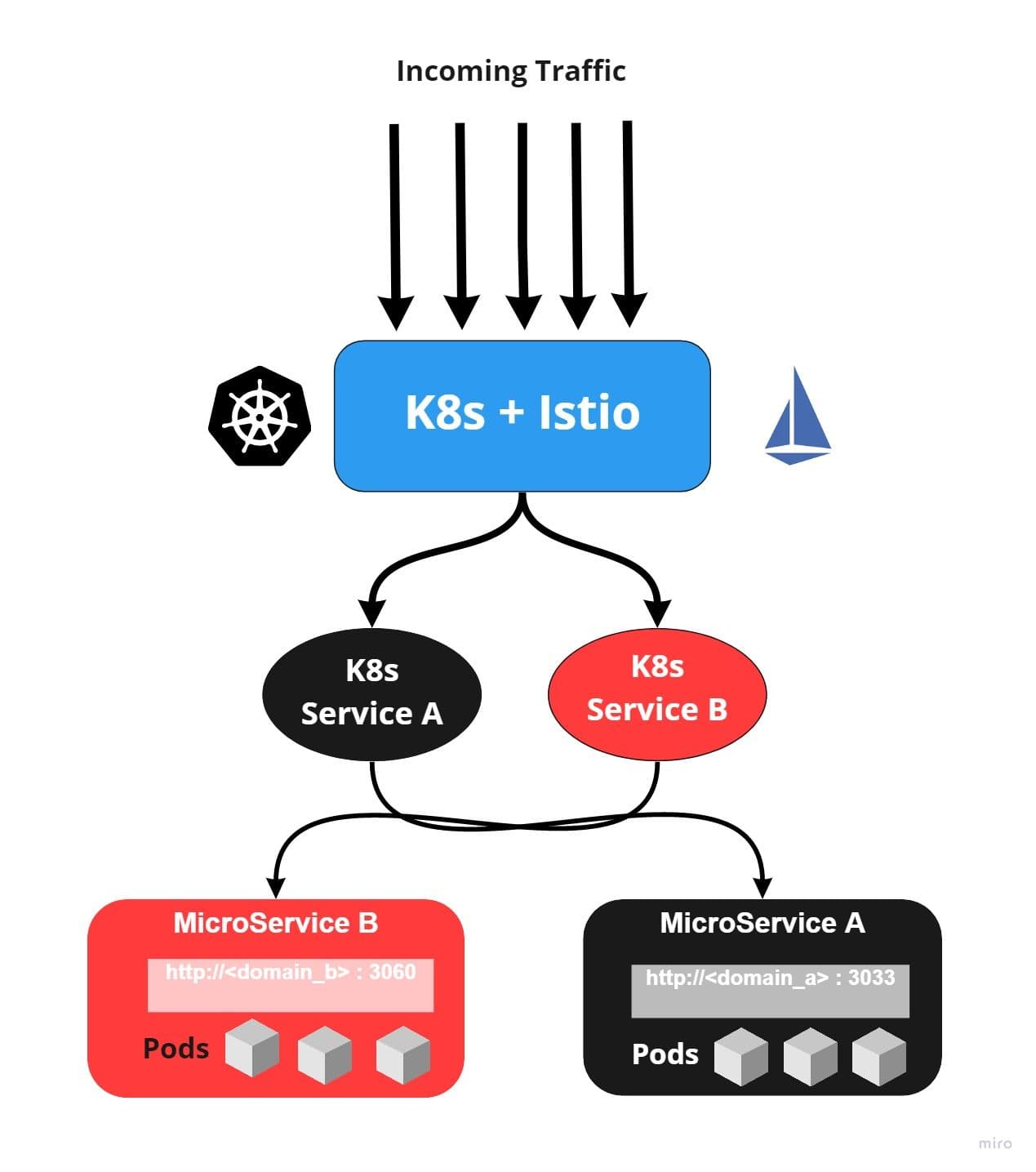
The app which complies with 12-Factor should be self-sufficient to accept client requests to the desired port. All application services would be bind and exposed with a port that will listen to incoming requests.
In Kubernetes, this portion is covered while designing containers. Containers of the same services expose to one port where they will listen to HTTP requests. This port will bind to Kubernetes services, which will pass incoming requests from Kubernetes’ services to underlying pods/containers. The image below illustrates the same.
This is an example of a docker file where can expose a port.
FROM node:alpine
# Create app directory
WORKDIR /home/myappservices
# Install app dependencies
RUN npm install
EXPOSE 8090 ## Your pods will listern to this port
CMD [ "npm", "start" ]This is an example of the service definition of Kubernetes
kind: Service
apiVersion: v1
metadata:
name: test-app-service
namespace: example
spec:
type: LoadBalancer
selector:
app: test-app-service
ports:
- name: http
protocol: TCP
port: 80 ### Port where K8s Services will listen to requests
targetPort: 80 ## K8s Forward requests to ContainersVIII. Concurrency
Scale out via the process model
This factor talks about the most critical concept of any application design, which is scaling. If the application is not scalable, the user experience will suffer eventually. This factor allows the application to design so that the application processes must be scale horizontally but not vertically.
If the application is supporting concurrency, each process of your application should scale independently and vertically. If this factor is not supported, you may have to scale up the complete application, which will be a costly affair.
Kubernetes has its own scaling mechanism, which can be applied to each microservices (aka process). The microservices can be scaled up and down based on memory, CPU, TPS, and queue length. In Kubernetes responsible module for scaling is HPA.
This diagram illustrates pods scaling as per traffic flow in Kubernetes for single process or microservices :
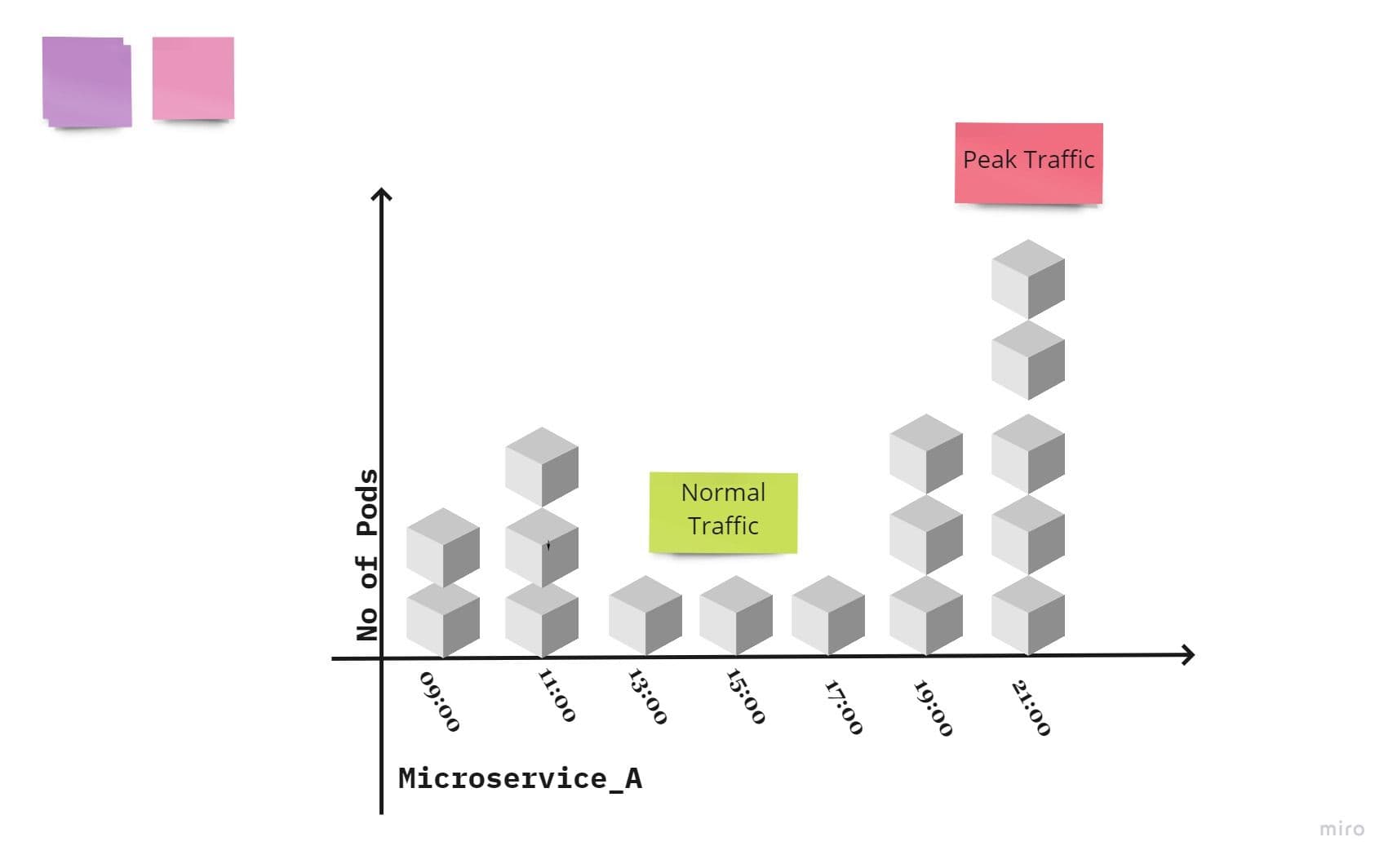
IX. Disposability
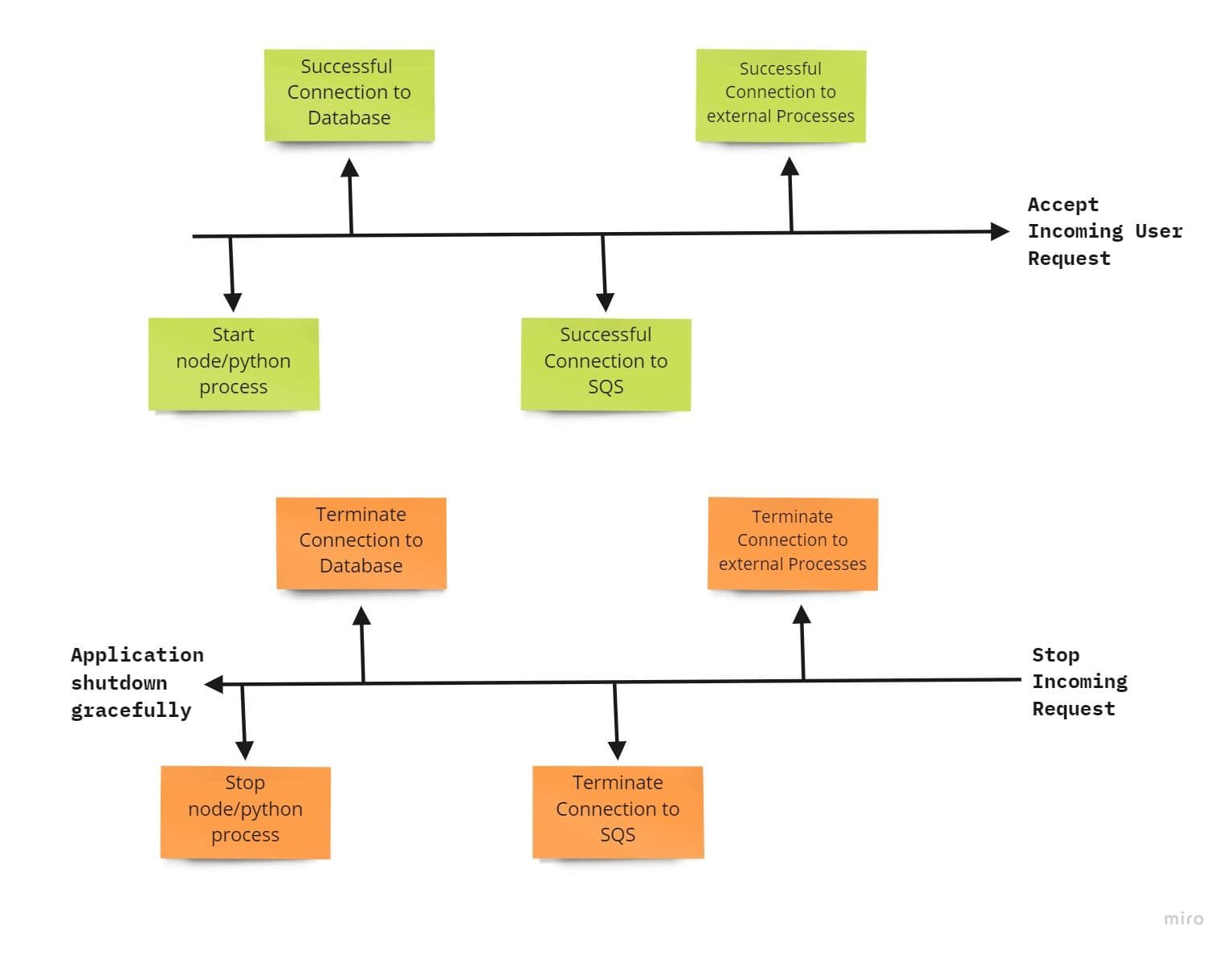
Maximize robustness with fast startup and graceful shutdown
This factor addresses how the app process should start and stop. The app process should start quickly and handshake with all external processes (like DB and queues) to maintain robustness.
If the process is killed or crashed, the external handshakes should also get terminated immediately, which should log the reason for failure or crash. This provides various benefits to the app, like quick code deployments, more agility for the release process, and robust production deployments.
It seems like this principle is designed for Kubernetes, as Kubernetes have this feature in build in terms of deployment and HPAs.Both will take care of seamless scaling and, at the same time, ensures the robustness of pods.
X. Dev/prod parity
Keep development, staging, and production as similar as possible
12 Factor advocates to keep same code in all environment, however backing services in all environment can’t be same, some gaps are unavoidable, those gaps factors into :
- The time gap: A developer may work on code that takes days, weeks, or even months to go into production.
- The personnel gap: Developers write code, ops engineers deploy it.
- The tools gap: Developers may be using a stack like Nginx, SQLite, and OS X, while the production deployment uses Apache, MySQL, and Linux.
However, DevOps Team should design all the environments (QA/Dev/Staging/Prod) with the same technology stack to minimize these gaps. However, the configuration will differ.
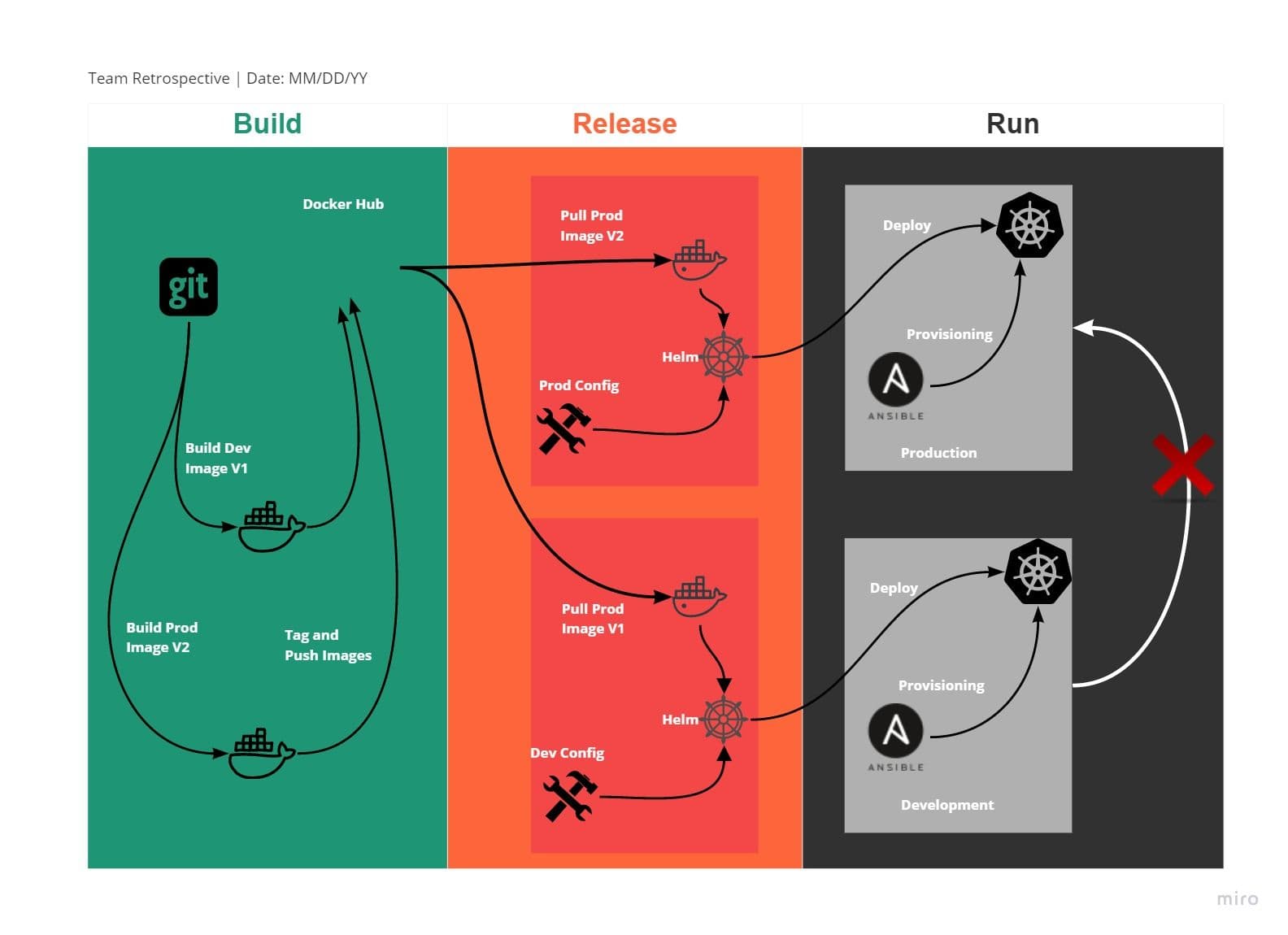
Now, Let’s assume you want to deploy a stable version of code (call it V1) to production and, at the same time, New feature requirement to be pushed to the Dev environment for testing(call it V2). CI/CD pipeline should deploy both deployments to the respective environment by applying the separate configuration, as illustrated in the image below. This requirement of 12 Factor has not much to do with Kubernetes as CI/CD will easily cater to this factor.
XI. Logs
Treat logs as event streams
Logging is a crucial part of any application. This factor talks about how the log should be preserve. The application should be responsible for generating logs. However, the application shouldn’t be responsible for storing, archiving, and analyzing the logs. Instead, logs should be treated as event streams. The run time environment will have to pass these streams to databases to store.
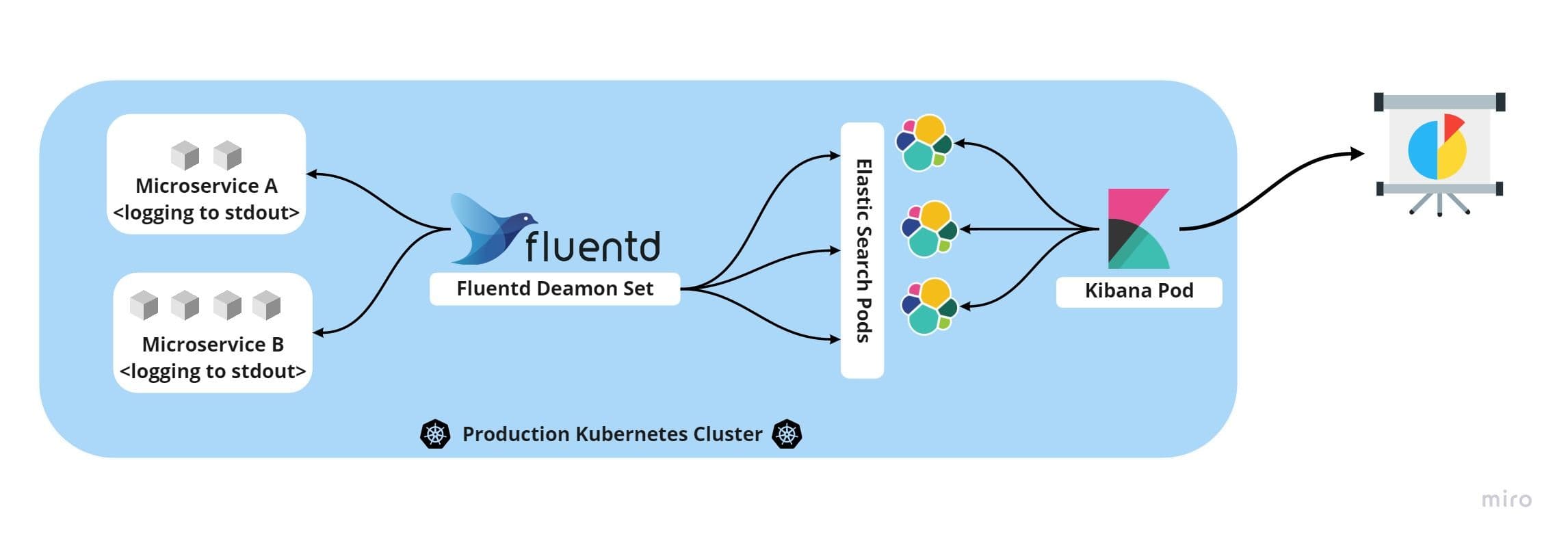
While the application is logging to standard output, open-source data collectors like fluentd can stream them to the database like elastic to store, analyze, and archive.
The complete stack of logging can be set up within the Kubernetes cluster, as illustrated in the image below, and do the job flawlessly!
XII. Admin processes
Run admin/management tasks as one-off processes
This principle talks about the admin processes and management tasks, which should be part of the same pipeline as the software lifecycle. Few examples of these processes are :
Running database migrations
- Running a console to check running app’s configuration parameters
- Running one-time scripts committed into the app’s repo
Admin processes should deploy the same way — application processes deployed in previous sections — applying all factors discussed before, such as release(factor V), using the same codebase(Factor I), and config(factor III). Admin code must ship with application code to avoid synchronization issues.
Going beyond the Twelve-Factor App Methodology
There are certain factors that are not included in the above TFA methodology. Take a look at these -
Telemetry —This is super-important when it comes to building cloud-native applications. Telemetry involves using special equipment to take specific measurements of something and then to transmit those measurements elsewhere using radio. There is a connotation here of remoteness, distance, and intangibility to the source of the telemetry.
Cloud applications are way different than building applications on a workstation. You don’t have direct access to your cloud application reason being it could be miles away. You can’t hammer or bang it to make it run correctly when problems arise.
In such situations, you need to know the kind of telemetry you need including the kind of data and remote controls you need to make sure your product runs successfully.
Security, Authentication & Authorization — When building cloud-native applications, it is easy to ignore these 3 factors. Too often, developers just focus on the functional aspects of the product. Your product needs to be secured. There are tools like OAuth2, OpenID Connect, various SSO servers, and standards, including countless language-specific authentication and authorization libraries. Security is the #1 thing that you should focus on right from Day 1.
API First — When you are building for the cloud, it goes without saying that your focus should be on having an app that is a participant in an ecosystem of services. You might be aware of the mobile-first approach. Similar to that API First implies that what you are building is an API to be consumed by client applications and services.
Why do we need this?
Well, because you don’t want integration nightmares.
Kevin Hoffman in his book Beyond the Twelve-Factor App writes -
API first gives teams the ability to work against each other’s public contracts without interfering with internal development processes. Even if you’re not planning on building service as part of a larger ecosystem, the discipline of starting all of your development at the API level still pays enough dividends to make it worth your time.
What to use for your next project Kubernetes or Docker?
We tend to get many questions surrounding which one should you use. Well, I say it isn’t a question about either. These technologies can complement each other very well.
A more relevant question would be docker Swarm v/s Kubernetes.
Docker Swarm focuses on clustering for Docker containers. It is integrated into the Docker ecosystem and has its own API.
While Docker runs on a single node Kubernetes runs across a cluster. It is known for coordinating clusters of nodes efficiently.
This is an interesting talk for anyone who wants to know more on Kubernetes and Docker.
Ending Notes
Developing cloud-native applications/SaaS products can be really tricky. However, using the latest methodologies, technologies, and a set of principles like the ones described above, building a world-class product is not impossible. Share your thoughts and experience in the comments. Cheers!